




В соцсетях и других медиа все чаще попадаются посты, которые легко заподозрить в отсутствии человеческого авторства. Интонация — как у автоматического переводчика без редактуры, фразы — будто из методички по контент-маркетингу. Формат схож: списки, советы, сводки, только без источников, ссылок и даже намека на автора. А еще манипулятивные эмоциональные заголовки, чтобы поймать на крючок внимание пользователя. Такой контент уже называют AI slop, в дословном переводе — «ИИ-помои». И да, его становится больше по экспоненте. Консультант по работе с нейросетями Наиля Аглицкая рассуждает о предпосылках и следствиях этого явления и об эволюции медиаграмотности.
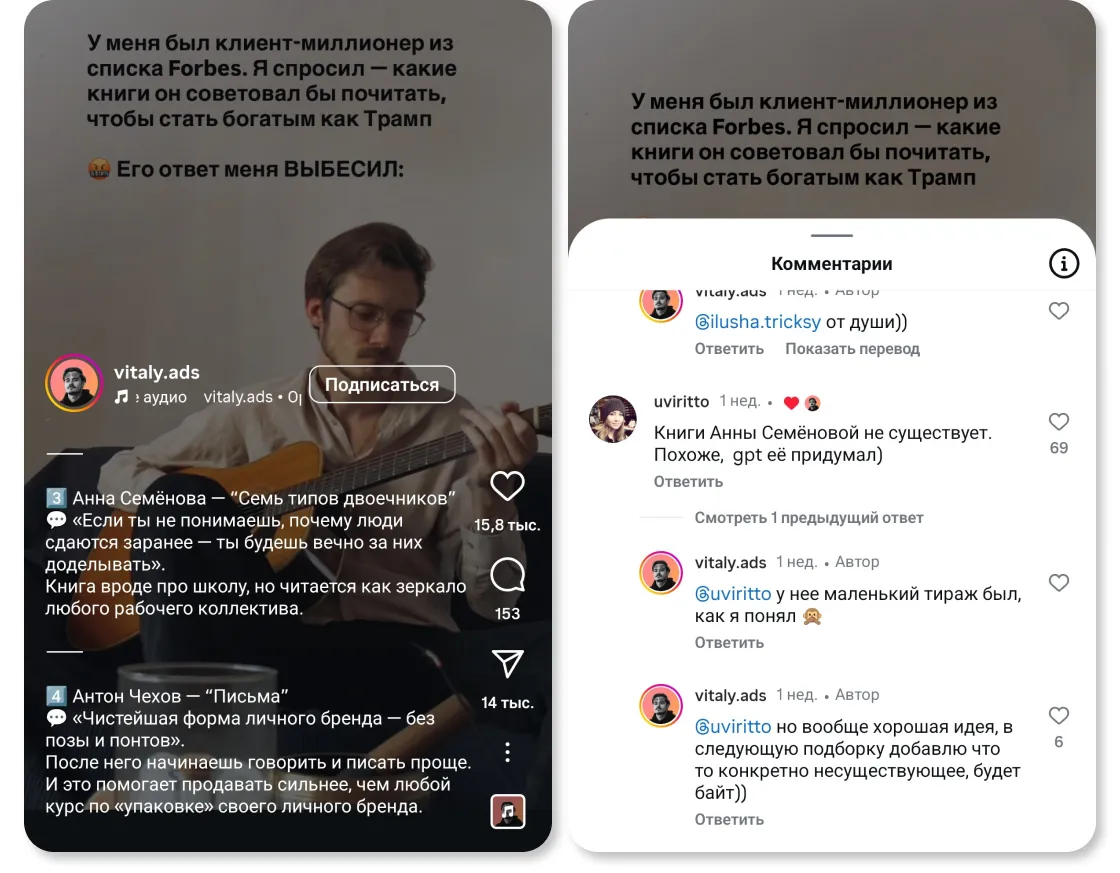
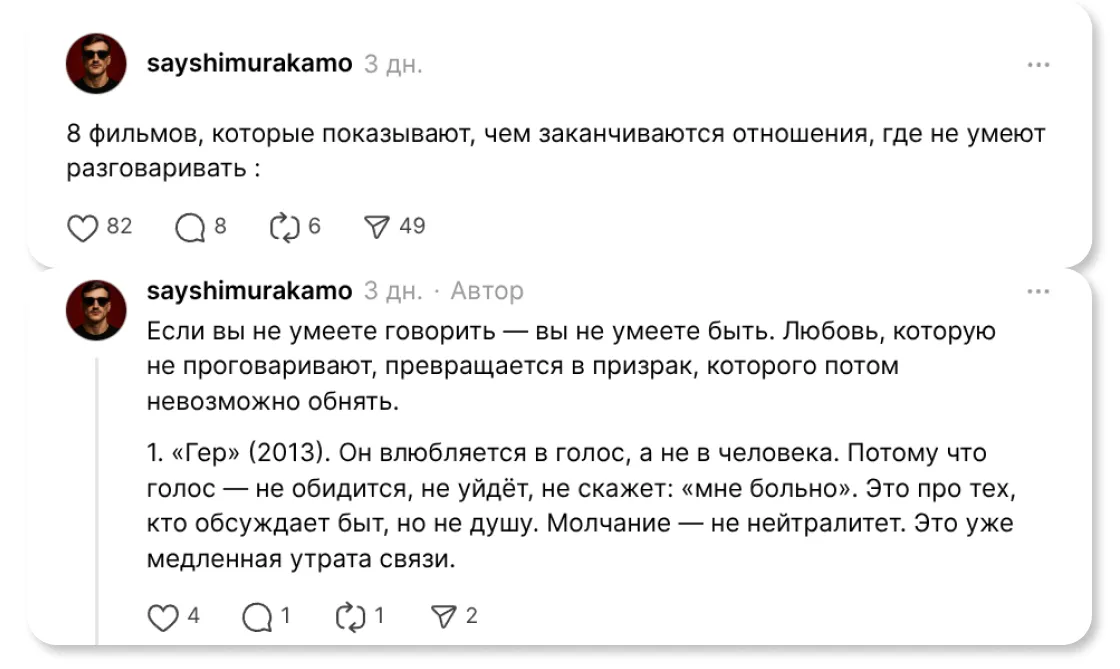
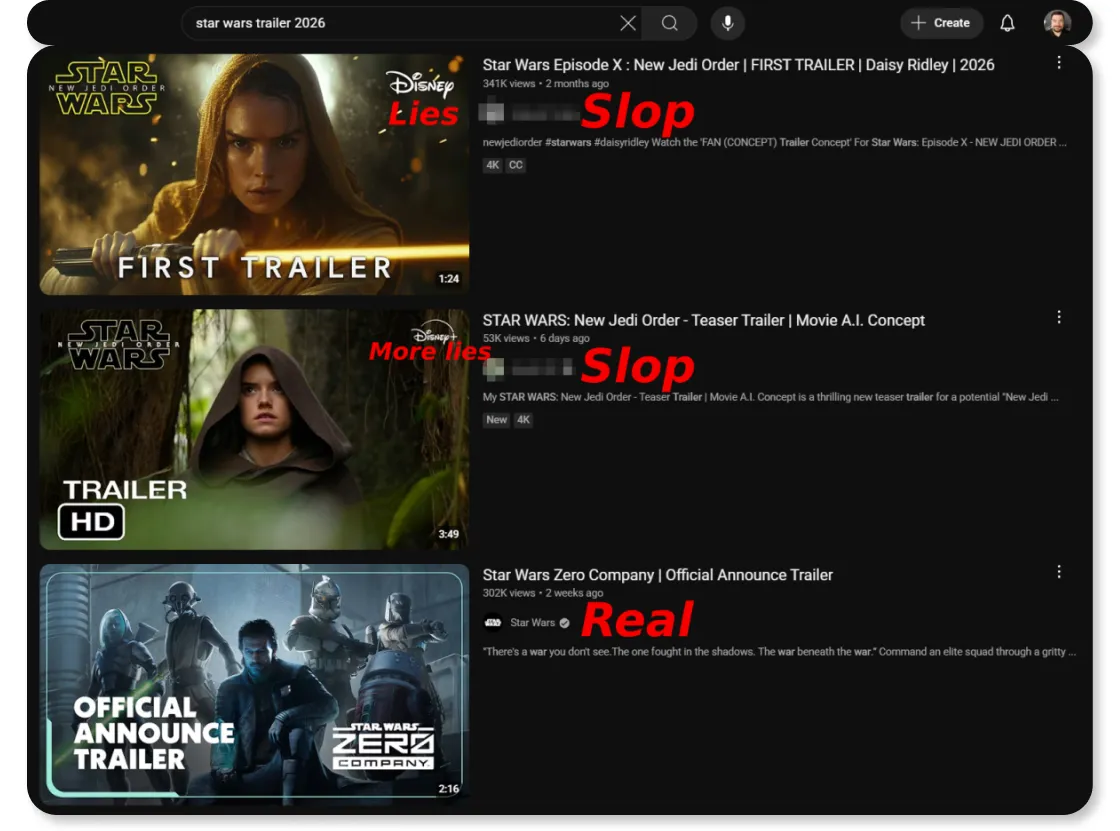
Недавно я наткнулась* на видео с подборкой полезных книг. Пост выглядел убедительно, но при проверке выяснилось, что некоторых книг попросту не существует. Автор в комментариях отмахнулся, что у них, вероятно, был маленький тираж. Но не настолько же маленький, что нет ни одного упоминания в сети? Это могло бы сойти за ошибку, но причина кроется в другом: судя по всему, пост был сгенерирован нейросетью и она выдала галлюцинацию вместо достоверной информации.
{{slider-gallery}}
Экономический ущерб от дезинформации ежегодно измеряется десятками миллиардов долларов, и это подсчитали еще до бума LLM‑технологий последних лет. Лавина ИИ-контента распространяется повсюду: половина длинных постов в LinkedIn сгенерирована, как и большинство вирусных политических фейков, показывают исследования Originality Al и CSIS.
{{slider-gallery}}

У подобного контента и себестоимость, и ценность стремится к нулю. Один промпт в нейросети даст десятки статей или постов. А с помощью no-code-инструментов легко запустить полноценный и бесперебойный контент-завод. Порог входа исчез, и теперь каждый, кто настроит цепочку автоматизации, может публиковать сотни текстов в день.
Более того, сегодня у сгенерированного контента нет четких правил: его редко проверяют на достоверность, почти не маркируют и плохо фильтруют, даже когда пытаются. В общем, публиковать ИИ-спам не просто легко — это можно делать без серьезных последствий.
Алгоритмические ленты усиливают этот эффект, подсовывая то, что формально попадает в круг интересов пользователя, и среди действительно полезного контента все чаще встречаются низкопробные генерации или несуществующие рекомендации. Но прежде, чем пользователь это поймет, он уже успеет вовлечься. Тот пост про несуществующие книги посмотрели почти 3 млн человек, но внимание было потрачено впустую.
{{slider-gallery}}
McKinsey считает, что формула успеха контент-маркетинга поменялась: раньше важно было, кто и в каком объеме увидел контент, теперь — кто ему поверил. Если пользователь просто «пролистал», то это лишь касание, которое без доверия к источнику сулит раздражение.
В эпоху информационной какофонии внимание ценно только в составе цепочки: внимание → восприятие → доверие → действие. И если где-то по пути возникает недоверие, то цепочка обрывается и контент оказывается бесполезным. IAS еще в 2022 году выяснил, что 73% потребителей испытывают неприязнь к рекламодателям, которые ассоциируются с дезинформацией, а 65% потребителей вряд ли что-то купят у такого бренда.
При этом удержать фокус, вызывать доверие и мотивировать к действию пользователей становится все сложнее: новые реалии провоцируют сомнения даже в том, что выглядит убедительно. Сегодня возникает состояние, когда видеть — значит не верить. Уже есть доказательства, что после взаимодействия с дипфейками пользователи хуже реагируют даже на подлинные публикации: снижается уверенность в своей способности распознавать манипуляции, а критическое мышление притупляется.
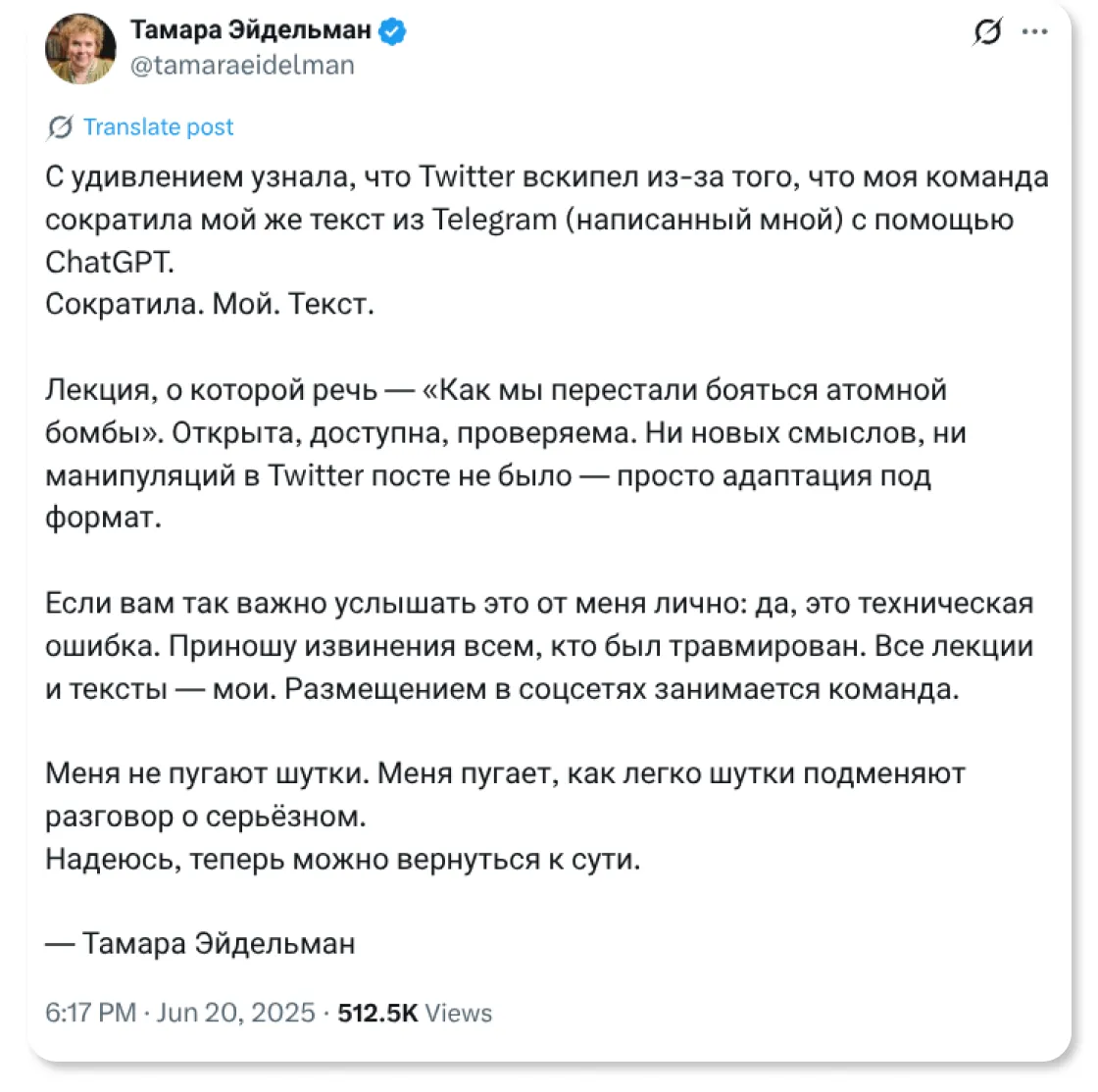
Недавний случай с историком Тамарой Эйдельман** стал симптомом этой новой безоглядной чувствительности. Один из ее постов в Х был отредактирован* с помощью ChatGPT, и при публикации осталась фраза «вот обновленный вариант в духе Тамары Эйдельман». В комментариях начался сущий кошмар: этой приписки было достаточно, чтобы публика восприняла текст как фейковый. Пост опирался на ее же мысли, опубликованные ранее в Telegram, и был просто переупакован, но восприятие сместилось: замешан ИИ, а значит, это неправда. В этом и кроется главная уязвимость сегодняшней медиасреды.
{{slider-gallery}}
Кроме того, при переизбытке данные не усваиваются, а просто блокируются — явление назвали «когнитивным перегрузом», это напоминает уже известную нам «баннерную слепоту». Но если последнее фильтровало только рекламные объявления, теперь критически осмыслять приходится буквально всю поступающую информацию.
Так что некачественный ИИ-контент демпингует доверие и к реальным авторам, и к медиаплощадкам, подрывая саму экономику внимания.
Дезориентация в инфошуме — ситуация не беспрецедентная. В истории каждый виток развития информации влек за собой медиапанику и временную утрату доверия, пока не формировались новые фильтры.
Когда-то печатный станок породил лавину памфлетов, а в ответ появились редакционные цензы, типографские марки и культурный сдвиг в сторону проверенного источника. Бульварные газеты, финансируемые рекламой, использовали гиперболизированные сенсации в борьбе за внимание читателя — почти что нынешний кликбейт. «Желтая пресса» манипулировала фактами и излишне драматизировала события. Тут, как следствие, произошла профессионализация журналистики и появились первые попытки кодификации этики СМИ.
Генеративный ИИ сегодня запускает очередной цикл. Контент перестает быть исключительно ручным трудом, любой желающий получил доступ к созданию и потреблению бесконечного потока убедительно звучащей информации — увы, не всегда реальной и тем более полезной.
{{slider-gallery}}
Важно уточнить: речь не о демонизации технологий. ИИ не породил этот шум с нуля, он лишь ускорил процессы, которые уже были в медиасреде. Контент давно девальвируется — сначала рекламной моделью, потом алгоритмическими лентами, потом гонкой за вовлеченностью. Нейросети лишь сняли последние барьеры: теперь не нужен даже человек, чтобы заполнить ленту чем-то убедительным на вид, но пустым внутри.
Разница с прошлыми циклами в том, что теперь масштаб инфошума, поляризации и недоверия к источникам стал неприлично быстро расти, притом что производственные затраты стремятся к нулю.
Другими словами, проблема не в технологии, а в ее встраивании: в отсутствии фильтров, сломанной логике платформ, привычке людей или верить на слово, или излишне не доверять. ИИ — катализатор, а не источник, он усиливает все: и плохие практики, и хорошие. И в этом смысле вопрос не в том, как его остановить, а в том, в какую культуру мы его встроим.
Каждый раз цикл развивается по знакомому сценарию: технологический взрыв → лавина инфошума → усталость аудитории → падение доверия. За этим следует неизбежный этап переосмысления и появления новых норм. Сегодня мы как раз на этапе перегрузки.
Баланс еще не восстановлен, но есть первые сигналы со стороны самих платформ: YouTube на днях объявил, что лишает монетизации «неаутентичные» ролики, а в прошлом году обязал маркировать сгенерированный контент. Но ключевой фильтр должен появиться снизу — на уровне читателя. Именно здесь возникает новая медиаграмотность — не как реакция на технологию, а как культурный навык выбирать, замедляться, сомневаться и различать.
Сориентироваться в потоке ИИ-шума помогут приемы, которые уже зарекомендовали себя для контент-гигиены. Одна из таких техник — [[SIFT|SIFT — аббревиатура от Stop, Investigate the source, Find better coverage, Trace the original context.]]. Она учит сначала остановиться на эмоционально резонансном заголовке: если присутствует сенсационность, обращение напрямую к читателю, использование категоричных формулировок, это сигнал внимательнее сопоставить факты с содержанием. Затем нужно проверить источник, найти другие публикации по теме и отследить первоисточник.
Это принцип горизонтального чтения: вместо того чтобы сразу углубиться в текст, мы сначала смотрим, что о том же говорят другие. ИИ-инструменты могут тут выступить «противоядием» — например, Perplexity, заточенный не на выдачу ссылок, а на краткие синтезированные ответы с гиперссылками на первоисточники. В отличие от привычных поисковиков, он помогает быстро получить обзор по теме, не теряясь в SEO-оптимизированных заголовках. Это не финальная инстанция, но как рабочий помощник на этапе проверки и ориентации годится.
Другой прием — [[CRAAP-тест|CRAAP — аббревиатура от Currency, Relevance, Authority, Accuracy, Purpose.]], который изначально предназначен для объективной оценки источников информации в академической среде, но будет уместен и для ориентации в ИИ-шуме. Предлагается ответить на вопросы: насколько свежа информация, насколько она релевантна в данном контексте, кто ее автор, насколько она подтверждена и с какой целью опубликована? Если наловчиться, начнете задавать себе эти вопросы и рационализировать, даже если просто смотрите рекламу или делаете репост.
Помимо методик, важен и собственный режим цифрового потребления: то, как мы настраиваем собственную онлайн-среду. Алгоритмические ленты удобны, но почти всегда заточены под вовлечение, а не достоверность. Поэтому лучше включать не случайный YouTube-ролик, а сохраненные подкасты, возвращаться к закладкам, а не к рекомендованному. Это поможет сохранить агентность.
Еще одна проверенная на личном опыте мера — вести свою инфокарту: список авторов, тем, ссылок, которым вы доверяете. Это может быть Telegram-папка или даже отдельный канал «для себя».
И наконец, разумный контент-детокс — не в духе цифрового аскетизма, а как профилактика перегрузки. Один день в неделю без ленты — только с тем, что выбрали вы сами: эссе, интервью или печатная книга.
Медиаграмотность сегодня похожа на здоровый скептицизм, где главный навык — умение включать фильтр собственного внимания. Но исторические циклы вселяют надежду — возврат к доверию неизбежен.
* Принадлежит корпорации Meta, признанной экстремистской и запрещенной в России.
** Признана Минюстом иноагентом.




