




Продолжаем цикл гайдов по генеративным нейросетям. В первом вы найдете обзор на популярные нейросети, а сегодня разбираемся, как с помощью ИИ быстро собрать сториборд, то есть визуальные концепты для самых разных задач без эффекта ИИ-слопа и не дороже ужина в кафе.
Это пригодится не только режиссерам, но и маркетологам, продактам, авторам курсов, блогерам, дизайнерам — в общем, всем, кто регулярно упаковывает идеи в визуал: от рекламных креативов до презентаций и мудбордов.
Раскадровка, она же сториборд, — это, по сути, покадровый план истории: что происходит, что меняется, какие детали важны, эдакий мост от сценария к реализации чуть ли не любой идеи. В мире до ИИ этот прием чаще ассоциировался с фильмами и видеорекламой — просто потому, что требовал немало ресурсов и не всегда оправдывал себя в задачах менее масштабных.
Например, еще пару лет назад, если вам нужно было разработать раскадровку для рекламного ролика или короткого метра, приходилось платить художнику примерно 500 рублей за один кадр, а кадров нужно было хотя бы десять. Потом ждать около двух недель и параллельно прикидывать, вырастет ли смета. Согласование превращалось в многострадальный пинг-понг: задачи «пинали» друг другу, переписывали, пересчитывали — и в итоге уходило много сил и денег даже на типовой проект. Позволить себе такое до 2025 года могли не все.
Теперь же можно зайти в Midjourney или ChatGPT, описать каждый кадр и сгенерировать изображение самостоятельно за пару минут: те же десять кадров обойдутся примерно в несколько сотен рублей (то есть примерно раз в десять дешевле!) и сама генерация займет всего 15–30 минут. Причем отрисовки вы получите в разных стилях, форматах, положениях героя или продукта — ИИ почти не ограничивает креатив, разве что количеством токенов. В общем, сейчас сториборд с ИИ — это универсальный и доступный инструмент для визуализации и коммуникации.
К тому же к 2025-му нейросети совершили главный прорыв — научились сохранять постоянство от кадра к кадру (при грамотном промптинге). Это критично, если собираете серию сцен с конкретным продуктом или героем. Словом, больше никаких шестых пальцев и красных шаровар вместо джинсов в следующем кадре, если персонаж повернулся на ¾ или встал спиной. Как и кошмарных массовых генераций «Уилл Смит ест спагетти», которые его самого, кажется, очень веселят.
Да, многие художники сделали галлюцинации нейросетей своей фишкой. Например, Рефик Анадол в проектах Machine Hallucinations превращает машинные сны в иммерсивные инсталляции. Марио Клингеманн экспериментирует с «ломаными» портретами, а Тревор Паглен, автор серии Adversarially Evolved Hallucinations, переосмысливает баги алгоритмов в абстракциях.
{{slider-gallery}}


Но это художники, а нам для практических задач чаще нужен реализм и адекватный креатив. Сегодня для этого все есть. Правда, расслабляться все равно нельзя: не стоит принимать первую же генерацию нейросети за финальный результат, даже если вы делаете не коммерческий продукт, а собственный мудборд.
По опыту, на создание пяти цельных кадров обычно уходит около восьми итераций. Сначала прописываю подробный промпт, потом докручиваю его в несколько заходов, переписываю куски, уточняю детали — и тогда получаю идеальный вариант. В некоторых нейросетях хватает и двух-трех генераций по одному промпту, но до этого особенно тщательно готовлю текст запроса.
Сторибординг способен прокачать даже самые обычные презентации — включая планерки, где хочется услышать «Вау, как круто!» от коллег. Ведь у всех мало времени, все хотят обсудить главное и пойти работать дальше. А четкое визуальное повествование (которое и обеспечивает качественный сториборд) не просто ускоряет понимание, но и увлекает, помогает лучше запомнить. Все это невозможно без визуальной гармонии: под ней понимаю и консистентность образов, и реализм, которые упоминала выше.
Во многом гармония в раскадровках с ИИ держится на трех столпах: подборке изначальных внятных референсов, контроле за единым стилем в процессе и самоконтроле (то есть готовности докручивать, а не бездумно принимать сгенерированное).
Вот основанный на этом пошаговый алгоритм.
В ИИ-генерации визуалов это навигатор, без которого невозможно добиться серийности, необходимой для сторителлинга. Другими словами, нейросети нужно дать четкий ориентир, чтобы она держала стиль от кадра к кадру.
Не ограничивайтесь одним референсом. Да, у некоторых нейросетей есть режимы вроде Omni Reference: можно буквально одной картинкой задать сразу все параметры. Но в большинстве сервисов референсы лучше развести — так снижается вероятность брака.
Для персонажей и маскотов (ищите функцию Character Reference или Character Lock). Заранее сгенерируйте героя в разных ракурсах (анфас, профиль, ¾) и с разными эмоциями. Загрузите эти кадры в нейросеть — тогда образ останется узнаваемым в любом сценарии.
Для ключевых объектов (ищите функцию Object Reference). Персонаж может быть отрисован идеально, но это не поможет, если на сгенерированных кадрах «плывет» окружение: магия легко рушится буквально от изменившейся вазы на заднем фоне. Поэтому соберите мини-гайды для всех ключевых объектов (элементы интерьера, упаковка и так далее).
Для локации (ищите функцию Structure / Composition Reference). Тут можно нарисовать или сгенерировать простой план сверху, чтобы ИИ понимал, где диван, а где окно, — тогда локация не поедет, даже если «камера» сменит угол обзора. Даже если нет какого-то конкретного заднего фона, важна композиция кадра: где объект, где фон, где воздух под текст (например, «товар — слева, место под заголовок — справа»).
Для общего стиля (ищите функцию Style Reference). Если персонажа и каких-то важных объектов в вашей раскадровке не намечается (скажем, вы просто хотите красивые единообразные слайды для презентации), все равно нужен «паспорт стиля». Подготовьте три-четыре эталонных изображения, которые идеально передают цветовую гамму, освещение и настроение (например, «киберпанк в пастельных тонах» или «корпоративный минимализм»).
{{slider-gallery}}

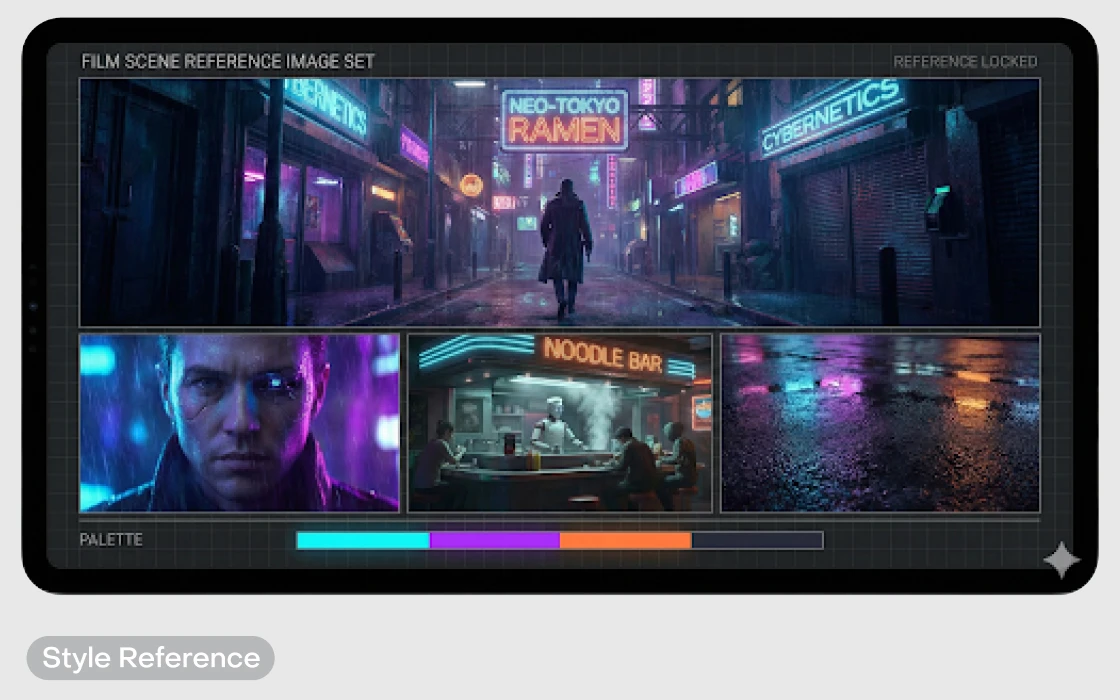
Когда путеводитель по образам и стилю готов, переходите к сборке самих кадров. Загрузите в нейросеть все картинки-референсы из шага 1. Чтобы точнее попасть в нужный результат, добавляйте и текстовый промпт — вот, на мой взгляд, идеальная формула: субъект/объект + действие + окружение (локация, погода, время суток) + стиль + техпараметры (формат / соотношение сторон / детализация).
И наконец, сгенерируйте ключевые сцены вашего проекта. Будьте готовы, что придется еще не раз корректировать и направлять нейросеть.
{{slider-gallery}}

Нужно убедиться, что сгенерированный ряд не выглядит хаотично: частенько цвета вроде бы дружат и образы похожие, но что-то не то — значит, детали скачут от кадра к кадру. Так, зритель может не заметить подвоха сразу, но если в одном кадре чашка круглая, а в следующем — овальная, он подсознательно почувствует фальшь. Такое случается, даже если внимательно подготовить изначальные референсы.
Пожалуй, самая частая ошибка ИИ тут — плавающий источник света. Так что не просто определитесь перед стартом — вам нужно «яркое солнце из окна слева» или «неоновая вывеска справа», — но и дальше следите, чтобы тени падали в одну сторону во всей серии. Иначе склейки и восприятие развалятся.
Лайфхак: когда изучите черновую раскадровку, доформулируйте «хвост» изначального промпта, который будет кочевать из запроса в запрос и удерживать нужный стиль на дистанции.
Важно: не забывайте про так называемые негативные промты (которые указывают, чего быть не должно в генерации). Этот блок тоже можно прикреплять к каждому запросу, чтобы случайно не вылезли артефакты, от которых вы уже избавились на первых слайдах.
Когда идеальный стиль найден, можно заставить ИИ строго следовать ему дальше — для этого ищите следующие опции.
Seed — это «код» генерации, лучший способ «заморозить» удачную композицию или черты лица маскота. Достаточно просто скопировать его и вставить в новый запрос (или включить Fixed seed — зависит от сервиса).
Inpainting — если нужно поменять простую небольшую деталь (например, цвет текста), сохранив остальное в кадре без изменений.
Image-to-Image — чтобы сменить картинку полностью, но с «якорем» на понравившуюся генерацию. Хорошо подходит для замены деталей посерьезнее (например, фона).
ControlNet — если нужен максимум контроля: позволяет копировать сложные детали вроде позы человека или глубины сцены. Настоящее спасение, когда нужно поместить один и тот же продукт в десяток разных локаций, не исказив его пропорции.
{{slider-gallery}}

Выбрать из многообразия нейросетей непросто. Один сервис подойдет для сложной видеорекламы и фильмов: точно передаст движение камеры, свет, удержит персонажей и атмосферу. Другой — для быстрой раскадровки презентации, мудборда или питча, чтобы не возиться часами, а сразу получить наглядные иллюстрации.
Ниже — самые удачные, на мой взгляд, инструменты для связных серий кадров. Они расположены по сложности: двигаемся от самых «режиссерских» к «бытовым», работающим как конструктор идей.
Эта платформа позиционируется как «помощник режиссера» (кстати, сделана казахстанцами и стала первым в истории страны ИТ-стартапом с оценкой более $1 млрд!). Внутри — каталог из 50+ предустановленных движений камеры, их можно применять как пресеты к сценам. Есть и генерация набора кадров с единым стилем, пиксельно-точное редактирование и турбо-режим.
Higgsfield агрегирует несколько моделей (в том числе Sora 2, Veo 3.1, WAN, Kling, Minimax и другие), поэтому ее удобно использовать как универсальный комбайн под разные задачи — в первую очередь для кинематографичных клипов.
По моему опыту, самый полезный инструмент для сторибординга здесь — Higgsfield Popcorn: он одним промптом собирает связанную серию сцен и хорошо стабилизирует персонажей и свет — без «мерцания» лиц и прыгающей экспозиции, типичных проблем современных генеративных нейросетей.
{{slider-gallery}}


Передовая модель Veo 3 от Google умеет создавать фотореалистичные видео до восьми секунд и дает ощущение полноценного продакшена: кадр, композиция, цвет, звук, динамика. Главная фишка для сторибординга — функция Add to scene: она помогает строить историю сцена за сценой, а не генерировать отдельные фрагменты.
Что еще удобно:
{{slider-gallery}}

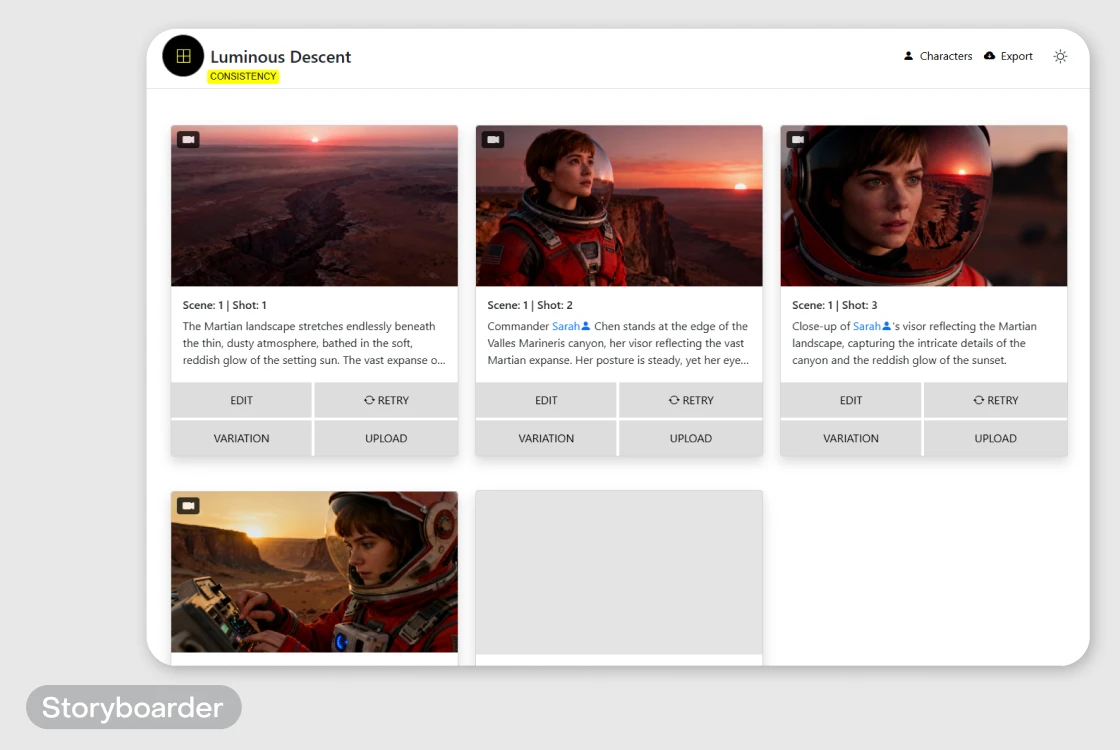
Менее популярная, но полезная платформа, если нужно быстро разложить идею по сценам: собрать цепочку визуалов из текста, прикинуть логику кадров и подготовить основу для обсуждения с командой или клиентом. Этот сервис специально заточен под раскадровки.
Чем хорош:
Правда, по качеству финальной картинки Storyboarder пока не конкурент Veo3. Но чтобы определиться со скелетом проекта — вполне себе.
{{slider-gallery}}
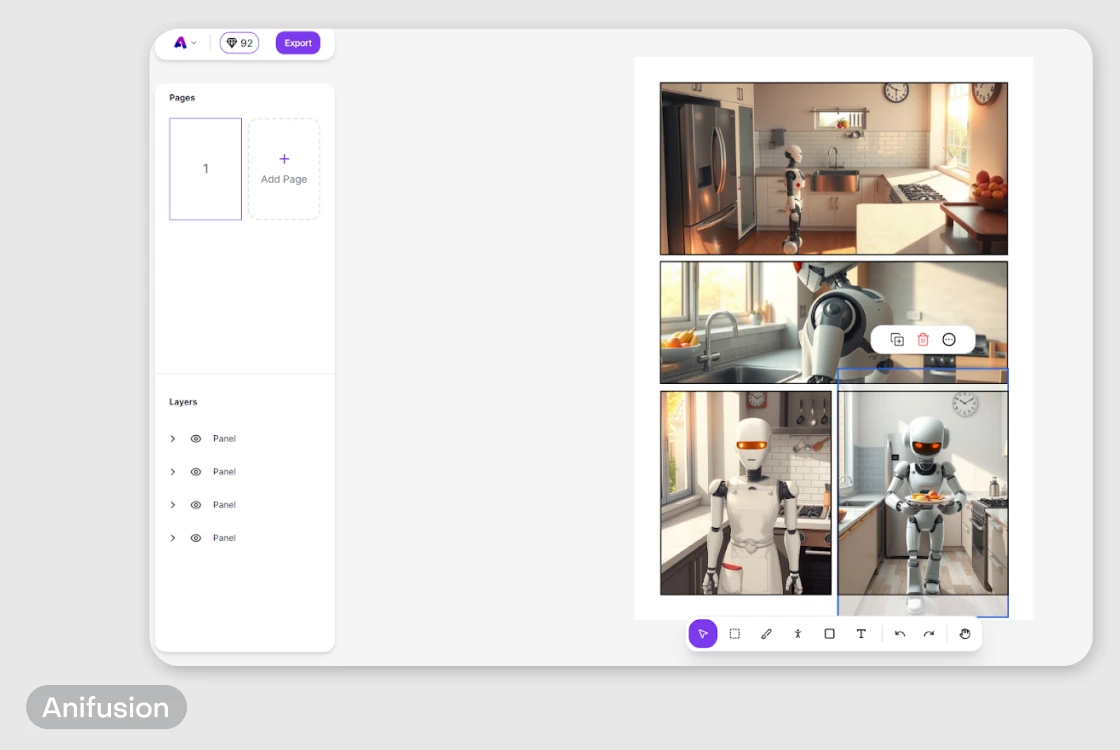
Хорошо собирает истории по текстовым промптам, упаковывает их в понятную визуальную форму. Чаще Anifusion берут для фэнтези и комиксов, но по факту это удобный инструмент для большинства рядовых сторибордов: можно набросать визуальный сценарий для курса, организовать серию кадров для контента в социальных сетях.
Что внутри: предзагруженные стили, возможность правок, добавление текста, выбор шрифтов и оформление. То есть вы не просто генерируете картинки, а сразу собираете страницы проекта.
По мощности и качеству также недотягивает до Veo 3, зато выигрывает простотой: понятный интерфейс помогает быстро превратить идею в визуальный нарратив, даже если вы не разбираетесь в дизайне и не хотите погружаться в сложные настройки.
{{slider-gallery}}
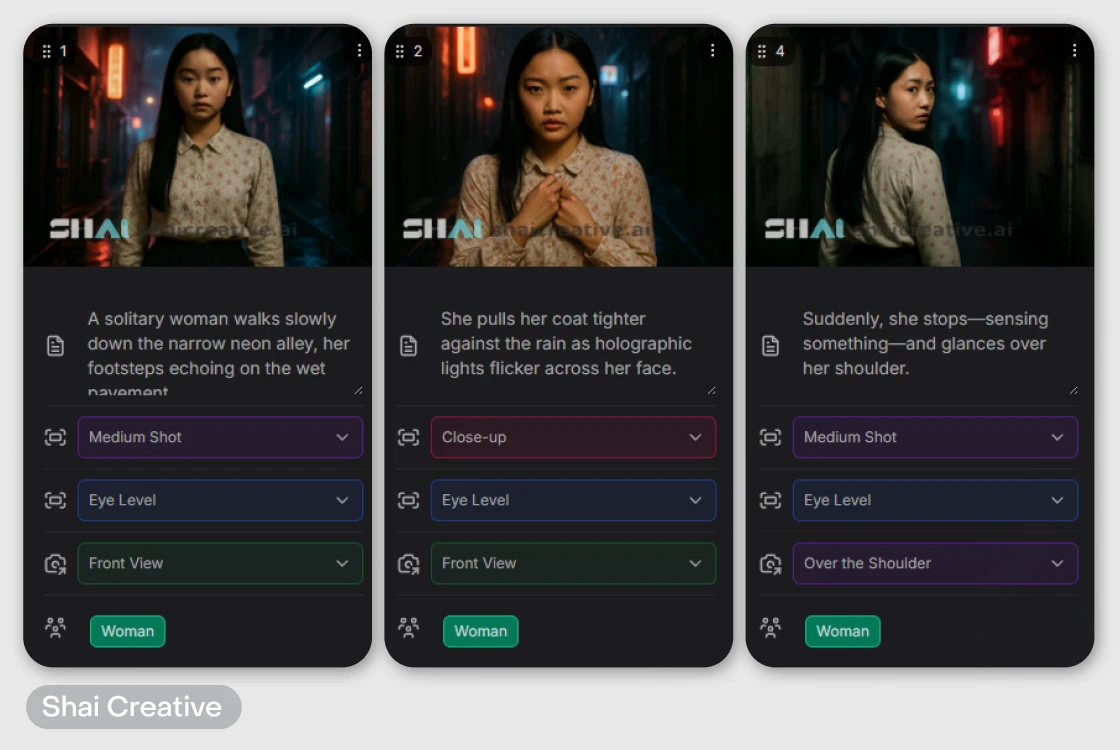
Shai Creative — инструмент для ситуаций, когда сториборд нужно обсуждать с коллегами и заказчиками: тут удобно обмениваться правками.
Или когда фокус на персонаже, но нет времени изучать нейросети сложнее. Можно сразу задать возраст, внешность, одежду — и дальше прогонять героя через разные сцены, не теряя узнаваемость.
{{slider-gallery}}
Как видите, ИИ-генерация сторибордов уже доросла до вполне профессионального уровня: реалистичные, даже кинематографичные раскадровки можно собирать за доступные деньги — и рекламному агентству, и небольшой инхаус-команде, и фрилансеру.
Но идеальную картинку по щелчку все еще не получить. Пока чаще прочего хромает физика движений: жесты, взаимодействие с предметами, логика тела. Эмоции и взгляд тоже иногда выглядят неестественно. И мне сложно представить, что это скоро исправится, что нейросети для генерации изображений и видео будут и дальше прогрессировать так же стремительно, как текстовые. Ведь у нашего визуального восприятия совсем другая чувствительность: люди видят с рождения; в отличие от навыков чтения и писания, тут у нас встроенный «детектор фальши» — и он срабатывает моментально.
Так что человеческое авторство в визуальном контенте, думаю, еще надолго останется центральным (по крайней мере, в сложных направлениях). Но ИИ уже отлично помогает: структурирует мысли, ускоряет процесс, тестирует идеи, оставляя человеку пространство мечтать, обдумывать и направлять. Если тут и есть формула будущего, то это симбиоз продуктивности ИИ и человеческой артистичности — той самой манкости и уникальности, которые и отличают сырую генерацию от авторской истории.




