



1938 году в книжных магазинах появился «Мировой мозг» — сборник эссе и лекций писателя-фантаста Герберта Уэллса. Это был своего рода манифест о будущем человеческих знаний.
Уэллс грезил о постоянно обновляемой «мировой энциклопедии» — едином репозитории, где ученые, политики и обычные люди находили бы достоверный ответ на любой вопрос. Такая система должна была помочь человечеству справиться с хаосом информации и избежать войн.
«Я говорю о процессе интеллектуального объединения мира, который, как мне кажется, столь же неизбежен, как вообще может быть неизбежно что-то в человеческих делах, — обращался Уэллс к публике на Всемирном конгрессе по универсальной документации в 1937 году. — Мир подобен фениксу: он гибнет в огне и, умирая, рождается заново. Этот синтез знания — необходимое начало нового мира».
А на излете XX века появился интернет (формально еще в 1960-х, но широкая публика получила к нему доступ только в 1990-х). Казалось, что теперь все когда-либо написанное, сказанное, снятое или опубликованное должно остаться в сети навсегда. Вскоре выяснилось, что это иллюзия.
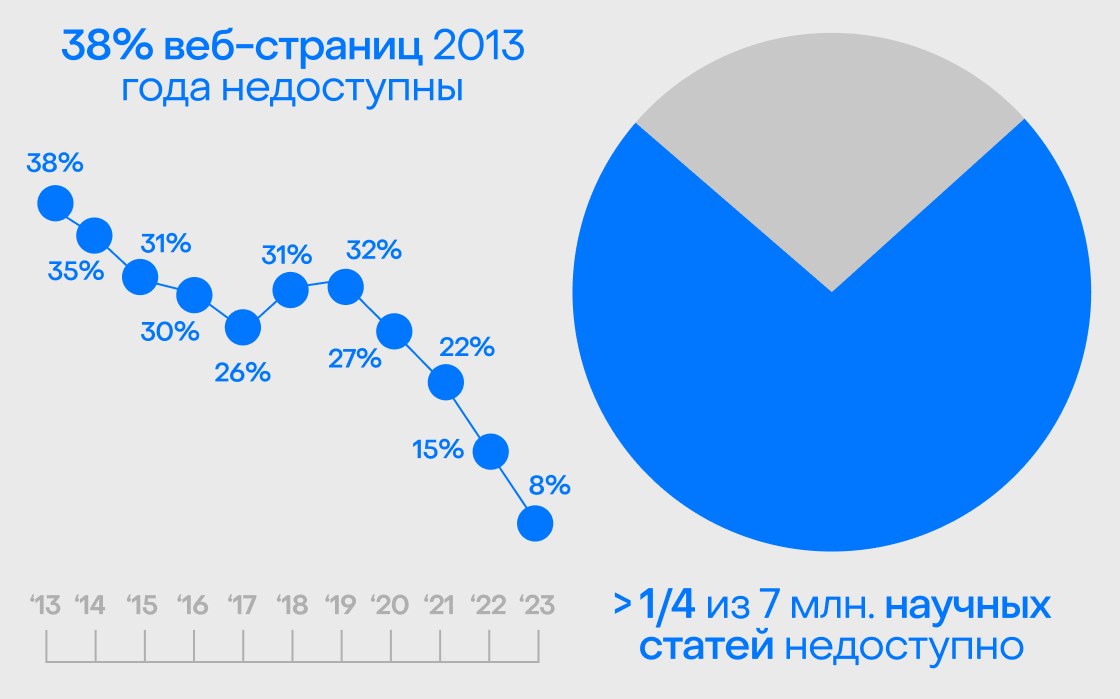
По данным Pew Research Center, сегодня недоступна примерно каждая четвертая страница из существовавших в 2013–2023 годах. Среди страниц тринадцатилетней давности исчезли 38%. Каждая пятая ссылка в новостях не работает, как и на госсайтах. Больше половины источников «Википедии» ведут в никуда. Не лучше дела и у юридических документов. Около половины URL в решениях Верховного суда США больше не ведут к исходным материалам. В Harvard Law Review и других профильных журналах — больше 70%.
Исчезают научные публикации, государственные отчеты, журналистские расследования — не остается даже архивных копий. Интернет не помнит все, как гласит расхожий мем, а постепенно забывает.
У этого явления есть точное название — link rot, или «гниение ссылок». Это тот самый момент, когда вы читаете старый материал, кликаете на гиперссылку — и попадаете в пустоту с надписью «404 Not Found». Причины такого положения могут быть самые разные: сайт переехал, домен не продлили или компания вовсе закрылась. В любом случае результат один и тот же — пустая страница, словно на ней ничего и не было.
Проблема глубже, чем кажется. Знаний становится все больше, а вот системы не поспевают их сохранять. Из 7 млн научных статей более четверти либо не были надежно заархивированы, либо уже недоступны. «Вся наша эпистемология науки и исследований опирается на цепочку сносок, — поясняет специалист по литературе, технологиям и издательскому делу Мартин Ив. — Если вы не можете проверить то, что кто-то другой сказал в какой-то другой точке, вы просто полагаетесь на слепую веру в артефакты, которые сами уже не можете засвидетельствовать».
{{slider-gallery}}
Никто не крайний
Пожалуй, главная причина того, что цифровой переход не решил проблему сохранности знания, о чем среди прочего грезил Герберт Уэллс, — в том, что ответственность размылась.
В эпоху печатных изданий хранение научных материалов было прежде всего задачей библиотек. Открытый не значит вечный: интернет эту систему разрушил, но не создал взамен новую (а ведь казалось, что именно технологии застрахуют мир от повторения участи Александрийской библиотеки). Кто должен отвечать за сохранность электронных архивов: издатели, университеты, библиотеки или сами авторы, — так и осталось неясным. Если ответственность распределена между всеми, то на практике ее не несет никто.
Оптимизация вместо смысла
Еще один маркер эпохи: интернет все больше заполняется контентом, созданным не для читателя, а для поисковых алгоритмов. Еще в 2023 году аналитики NewsGuard описали, как крупные бренды невольно финансируют сайты, публикующие сотни ИИ-сгенерированных текстов в день. Это происходит через систему рекламы: объявления на популярных страницах размещаются автоматически, а качество или происхождение контента значения не имеет.
Институт Reuters по изучению журналистики при Оксфорде предупреждает, что такой контент превращается в цифровой шум. Сайты создаются не для информирования аудитории, а для максимально дешевой оптимизации под поисковую выдачу. В итоге материалы профессиональных журналистов и исследователей рискуют раствориться в потоке пустых текстов.
Весной 2024 года Google объявила о крупном обновлении поискового алгоритма, направленном против страниц, созданных «прежде всего для поисковых систем, а не для людей». Цель благая — сократить долю некачественного и неоригинального контента в выдаче на 40%. И уже сам факт такого вмешательства показывает, насколько массовым стало явление.
Потом, такие материалы сами по себе недолговечны. Пока сайт приносит рекламный доход, он существует, но как только поток трафика иссякает, домен закрывается и уходит в небытие. Так интернет постепенно пополняется еще одним типом цифровых руин.
{{slider-gallery}}

Политика 404
Отдельная угроза не техническая, а политическая. С начала второго срока Дональда Трампа на федеральных сайтах США были удалены или существенно изменены более 8 тыс. страниц и около 3 тыс. датасетов. Данные о климате, здравоохранении, расовой статистике, гендерной идентичности и ВИЧ исчезли за несколько дней после указов президента.
В феврале 2025 года федеральный суд обязал регуляторов восстановить часть удаленного контента — и некоторые материалы вернулись. Но сам прецедент оказался важнее: в цифровую эпоху переход от смены политического курса к стиранию неугодной информации может быть очень быстрым. В отличие от печатных книг, которые невозможно изъять из всех библиотек сразу, веб-страница (особенно государственная) может исчезнуть за секунды.
Серьезные проблемы с данными наблюдаем и в России. После февраля 2022 года в 48 федеральных ведомствах скрыли около 1 тыс. датасетов, замечает проект «Если быть точным». Пик пришелся на 2022-2023 годы, когда исчезли чувствительные данные об экономике, о преступности и смертности. А в 2025-м сильно пострадала демографическая статистика: в открытом доступе больше нет данных по бракам, разводам, рождениям и численности населения.
{{slider-gallery}}

В октябре 2025 года Internet Archive, крупнейший архив человеческой памяти из когда-либо существовавших, перешагнул отметку 1 трлн сохраненных страниц — примерно по 125 на каждого живущего сейчас человека. Судя по всему, это на порядок больше веб-коллекций крупнейших библиотек мира.
Этот архив основал Брюстер Кейл в 1996 году в Сан-Франциско с простой и почти утопической миссией: «Всеобщий доступ ко всем знаниям». За три десятилетия организация превратилась в один из самых посещаемых некоммерческих сайтов мира с годовым бюджетом $20+ млн*. А еще смогла накопить 200+ петабайт данных. Для понимания: аренда на год тех же 200 петабайт на коммерческих серверах Amazon S3 по стандартным тарифам вышла бы примерно в два раза больше годового бюджета архива.
*Бюджет архива складывается из поддержки фондов и частных доноров.
Выживать проекту помогает изобретательность, доведенная почти до аскезы. Серверы архива собирают по собственным чертежам: инженеры разработали систему хранения PetaBox — это высокоплотные и энергоэффективные стойки с тысячами жестких дисков — в совокупности известные как Wayback Machine. Часть их стоит в старой церкви в Сан-Франциско. Они хранят память человечества (около 150 ТБ важных данных каждый день!) и заодно отапливают здание.
Internet Archive руководствуется принципом LOCKSS, или Lots of Copies Keep Stuff Safe, то есть надежность через избыточность. База данных существует сразу в нескольких физических копиях, распределенных по разным точкам планеты — от Африки* до Канады, чтобы локальная катастрофа не могла уничтожить коллекцию целиком. В 2025-м у архива появилась штаб-квартира в Амстердаме.
*Кстати, в нулевых Wayback Machine сделал и резервную копию возрожденной Александрийской библиотеки в Египте.
Жизнеспособность такой архитектуры подтвердили хакерские атаки в 2024 году. 9 октября группа SN_BlackMeta (многие их считают хакерами-вандалами, сами они себя называют политическими активистами) перегрузила архив потоком ложных запросов и взломала базу пользователей через уязвимость в одной из библиотек. Архивные данные и их резервные копии не пострадали, и в итоге Internet Archive выстоял.
В июле 2025-го калифорнийский сенатор Алекс Падилья присвоил архиву статус федеральной депозитарной библиотеки — впервые в истории это звание получила цифровая организация. «Это позволяет нам стать ближе к источнику, откуда поступают материалы», — объяснил Брюстер Кейл.
Однако этот шаг во многом символический: новый статус не дает дополнительного финансирования и не ограждает от исков по авторскому праву. Архив продолжает балансировать между своей миссией и юридической реальностью, как, впрочем, и с первого дня своего существования. Правда, соблюсти баланс удается не всегда.
{{slider-gallery}}

В 2020 году четыре крупнейших американских издательства — Hachette, HarperCollins, Penguin Random House и Wiley — подали иск против Internet Archive за практику «контролируемого цифрового кредитования». Архив покупал бумажные книги, сканировал их и выдавал бесплатный временный доступ к цифровой версии по принципу «один купленный бумажный экземпляр = один файл в одни руки» — почти как в обычной библиотеке. Издатели назвали это пиратством.
Уже в марте 2023 года суд встал на сторону издателей, а в сентябре 2024-го Апелляционный суд второго округа подтвердил решение: оцифровка физической копии книги нарушает права издателей и авторов. Потому что, как постановил суд, подобный интернет-архив «не является трансформативным, не добавляет нового выражения, смысла или послания к оригинальным произведениям», а просто копирует и распространяет контент без разрешения правообладателей. Архив не стал подавать апелляцию, более 500 тыс. книг пришлось удалить.
Критики решения предупреждают о прецеденте. «Библиотеки и без того задавлены лицензионными сборами за электронные книги, — заявил Дэйв Хансен, исполнительный директор Authors Alliance. — Это решение может принести пользу лишь крупнейшим издательствам и самым известным авторам, но для остальных оно обещает больше вреда. Оно может даже задушить академические исследования и обучение в целом».
Параллельно обострился конфликт с музыкальной индустрией. Пару лет назад лейблы Universal Music Group, Sony Music Entertainment и Concord подали иск на $621 млн против Internet Archive из-за оцифровки старых грампластинок в рамках Great 78 Project*. В защиту архива выступили более 600 музыкантов, а петиция об отзыве иска собрала 125 тыс. подписей. В сентябре 2025 года дело было урегулировано на конфиденциальных условиях.
*Это проект по сохранению старых граммофонных пластинок на 78 оборотов в минуту — так называемых 78s. Такие пластинки были основным музыкальным форматом примерно с конца XIX века до 1950-х годов.
Шведский стол для бигтехов
Одновременно разворачивается новый скандал. Издатели начали блокировать краулеры интернет-архива, но не потому, что выступают против архивирования как такового. Проблема в другом: открытые архивы превратились в удобный источник данных для ИИ-компаний.
И действительно, пока новостные сайты закрывают прямой доступ ИИ-ботам и агентам и подают иски против разработчиков моделей, те все чаще переключаются на публичную инфраструктуру — архивы и индексы, потому что именно они по определению остаются открытыми для машинного доступа. В результате давление, изначально направленное против ИИ-гигантов, смещается на институты цифровой памяти.
Логика медиаиндустрии здесь вполне последовательна: доступ к контенту должен быть платным. В Gannett (владелец USA Today и сотен региональных газет) сообщили, что ежемесячно блокируют десятки миллионов запросов от ИИ-ботов, значительная часть которых связана с OpenAI. При этом сам концерн одновременно подписал лицензионные сделки с Perplexity.
Архив в этой схеме смотрится не врагом, а неудобным посредником: он не берет денег за доступ и не может контролировать, кто им пользуется. Дело Hachette vs Internet Archive выявило более широкое противоречие: чем сильнее правообладатели ограничивают доступ ИИ-компаний к своему контенту, тем больше нагрузка на публичные архивы и библиотеки. Иронично, но так бастионы открытого цифрового знания оказались в заложниках у собственной открытости.
Международные организации заговорили о цифровой памяти давно, но эти обсуждения так и не оформились в цельную систему регулирования.
Если глобально, то хартия UNESCO об охране цифрового наследия признает, что авторское право настолько ограничивает копирование, что даже перенос файлов в библиотечные системы может нарушать права правообладателей. Отдельно оговаривается, что без сотрудничества издателей, архивов и библиотек долгосрочное сохранение цифрового наследия практически невозможно. К практике дело пока мало продвинулось.
Хотя некоторые страны все же начали создавать инфраструктуру цифровой памяти. Великобритания обязала крупные интернет-ресурсы передавать контент в Британскую и другие библиотеки. Германия и Австралия развивают свои государственные веб-архивы. В США принятый в 2019 году OPEN Government Data Act предписывает агентствам публиковать данные в машиночитаемом формате — правда, ничто не мешает их удалять.
Видимо, наше наследие — это не эксабайты бесценных данных, а умение вовремя делать нужные скриншоты.




